Learning Personal Style from Few Examples
Human-Computer Interaction Institute, Carnegie Mellon University
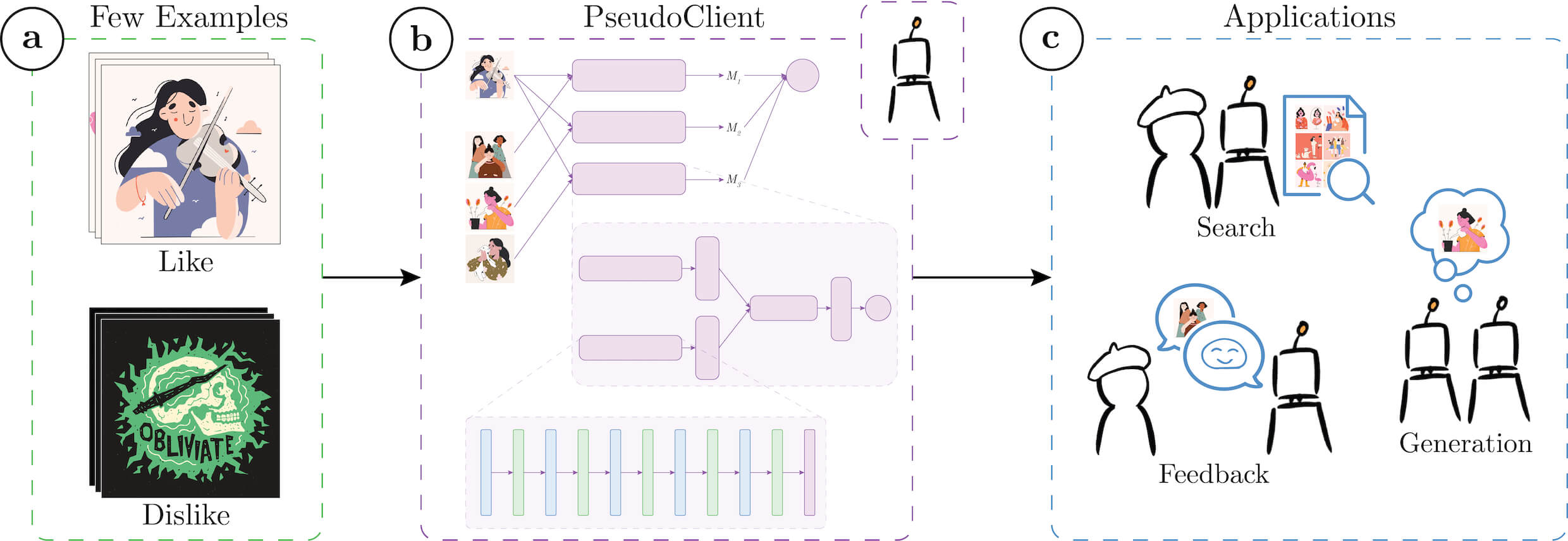
Given a few design examples (a), PseudoClient learns a computational model of the client's personal style preferences (b) to support multiple practical design applications (c).
Abstract
A key task in design work is grasping the client's implicit tastes. Designers often do this based on a set of examples from the client. However, recognizing a common pattern among many intertwining variables such as color, texture, and layout and synthesizing them into a composite preference can be challenging. In this paper, we leverage the pattern recognition capability of computational models to aid in this task. We offer a set of principles for computationally learning personal style. The principles are manifested in PseudoClient, a deep learning framework that learns a computational model for personal graphic design style from only a handful of examples. In several experiments, we found that PseudoClient achieves a 79.40% accuracy with only five positive and negative examples, outperforming several alternative methods. Finally, we discuss how PseudoClient can be utilized as a building block to support the development of future design applications.
Video Summary
~6 minute read
Background
A designer needs to understand the client’s personal style. For example, some clients may prefer playful, or vibrant designs while others may prefer more hardcore, heavy metal designs. Designers often gain a sense of this "personal style" based on a few examples from the client.
However, especially for newer junior designers, recognizing a common pattern among many intertwining variables such as color, texture, and layout and synthesizing them into a composite style preference can be challenging.
In this paper, we ask: Can we learn a computational model of personal style from only a few examples?
Approach
We frame our task of modeling the client’s personal style from a few examples as a metric learning problem. In other words, given an arbitrary test design we want to evaluate, our objective is to determine its similarity with a set of representative examples selected by the client. This allows us to then classify the test design between two classes: client likes or client dislikes. Our resulting computational model predicts a match score, which is how well the test design matches the client’s liking.
Contributions
In summary, our contributions are three-fold:
- We first distill a set of principles for computationally learning personal style.
- We then manifest the principles in PseudoClient, a deep metric learning framework for personal graphic design style. Our experimental results show that PseudoClient outperforms several alternative methods and can also be adjusted for different designer needs.
- Finally, we discuss how PseudoClient can be used as a building block for multiple practical design applications.
I. Principles of Learning Personal Style
We ground the design of PseudoClient in four central principles, synthesized from prior work in design, recommender systems, and cognitive psychology.
- Learn by Example. Considering that design vocabulary (such as playful or elegant) is inherently subjective and highly dependent and interpreted based on the individual’s knowledge and experiences, we do not ask clients to indicate their preferences through such vocabulary nor do we attempt to fit their preferences into such vocabulary. Inspired by the mood board technique, we simply ask the client to supply us with visual examples and learn to judge the client’s personal style based on them.
- Learn by a Handful. Since our task is to learn personal style, our examples come directly from the client of interest. However, asking the client to select massive amounts of examples is tedious. Therefore, rather than being data-hungry, PseudoClient should be capable of working with only a handful of examples.
- Learn by Juxtaposition. Prior work in recommender systems suggest that it is easier for clients to select positive and negative samples than to judge likeability on a spectrum. Therefore, we simply ask the client to provide us with some examples they like and some examples they dislike.
- Learn by Multiple Comparisons. Studies in the learning sciences and cognitive psychology have observed that through repeatedly doing pairwise comparisons, one can quickly learn a common underlying structure of a pool of examples. We build on this insight in PseudoClient’s design.
II. PseudoClient
Based on the principles, we designed PseudoClient, our computational model for learning personal style. PseudoClient takes in a test design and outputs a final Match Score between 0 and 1, which estimates how well the test design aligns with the client’s personal style. PseudoClient consists of three levels of components: the Comparison Framework, which contains the Juxtaposition Network, which further contains the Embedding Network. The following briefly summarizes each of the components. For further details, please refer to our paper linked at the top of the page.
- Comparison Framework. The Comparison Framework takes in a test graphic design we want to evaluate and a small pool of graphic design examples the client likes. We then perform pairwise comparisons between the test design and each reference design in the pool to compute their respective Match Scores. Our final match score is the median of all the pairwise match scores. A high final Match Score implies that the test design matches the client’s personal style, and vice versa.
- Juxtaposition Network. Individual match scores are computed by the Juxtaposition Network, which takes in the test design and a reference design, and outputs the Match Score based on the designs’ distances in a learned embedding space.
- Embedding Network. A design’s learned embedding space is computed by the Embedding Network, which takes in a design and outputs its Feature Embedding.
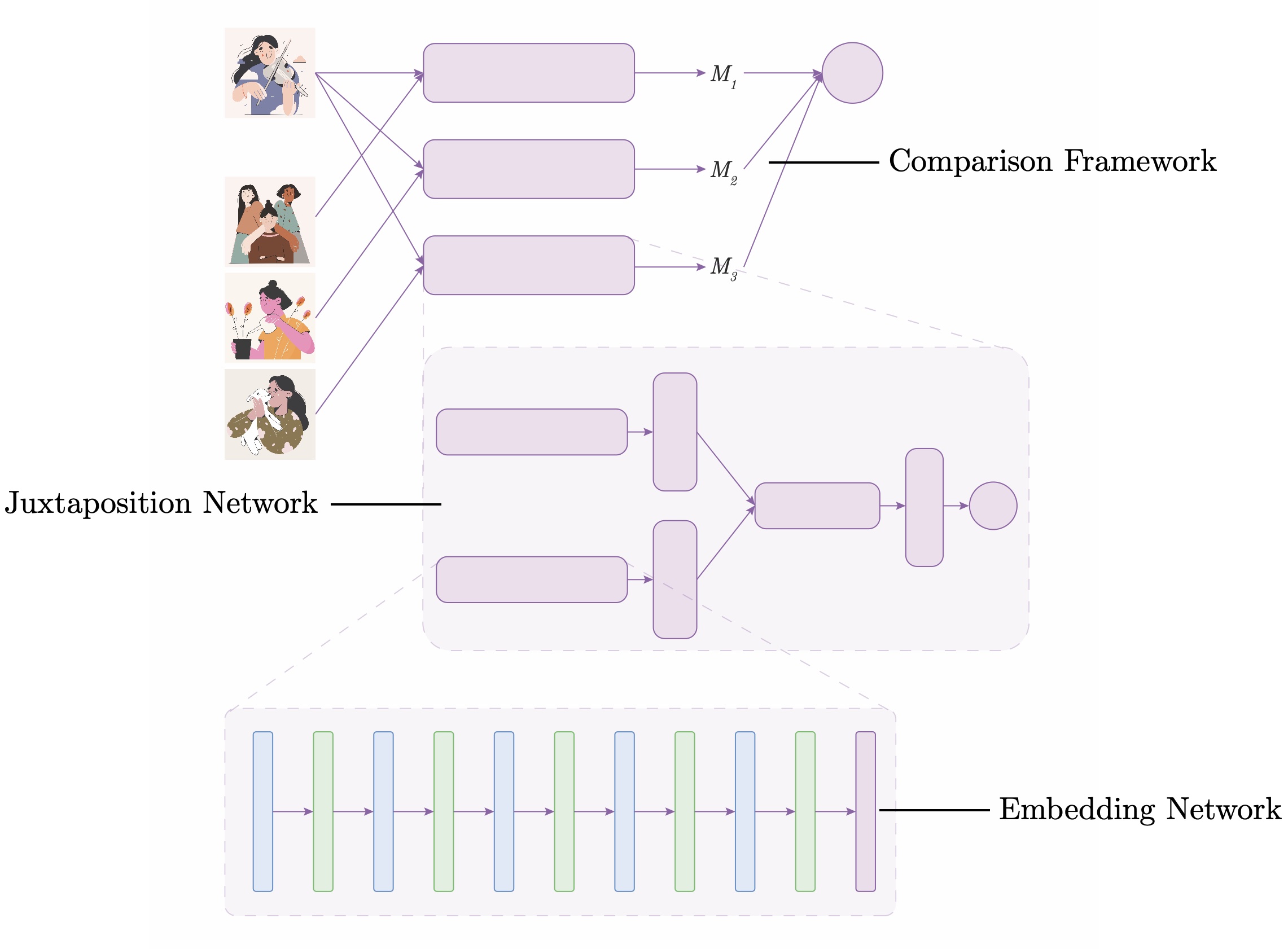
Overview of PseudoClient, our computational model for learning personal graphic design style.
Experiments
We performed several experiments to evaluate PseudoClient’s performance. We first trained five personalized models for five people. Each personalized model was trained with only five positive and negative design examples. We compared PseudoClient against two common baselines (color histogram distance and a standard convolutional neural network) and we can see that PseudoClient outperforms them. PseudoClient’s performance also improves as we increase the number of design examples available for referencing. By giving different ratios of like and dislike design examples, designers can focus on optimizing true positive accuracies or true negative accuracies. For example, a designer can focus on optimizing true negative accuracies to really avoid producing a design that the client’s dislikes.
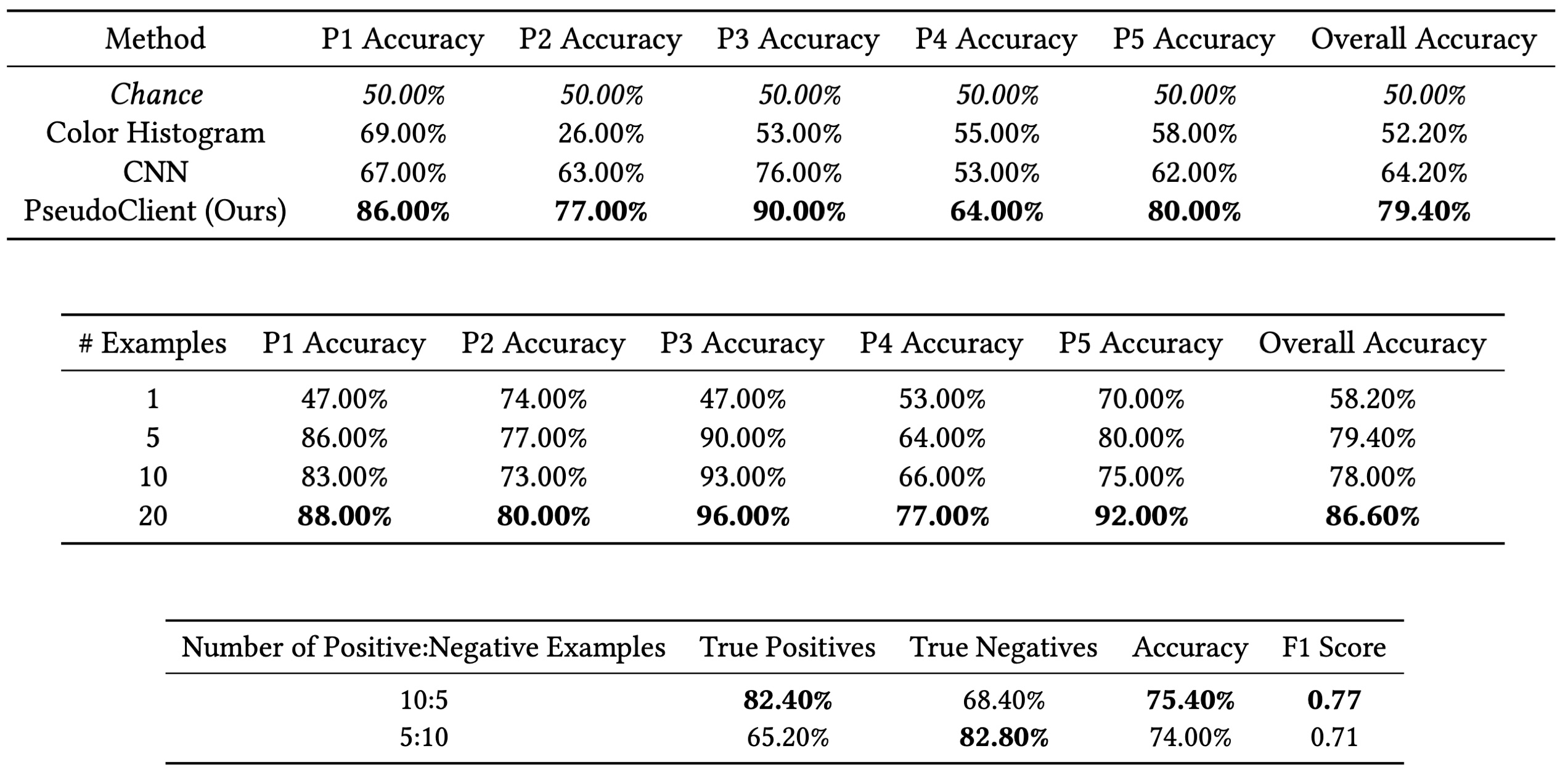
From top to bottom: (1) The accuracies of different methods between participants P1 to P5 and overall. (2) The accuracies of PseudoClient when given different numbers of examples between participants P1 to P5 and overall. (3) The overall true positive percentages, true negative percentages, accuracies, and F1 scores of PseudoClient when given different ratios of positive and negative examples. The highest results are highlighted in bold.
Given five examples from the client, we demonstrate searching from a database of graphic designs from dribbble.com for the top-10 designs with highest match scores.
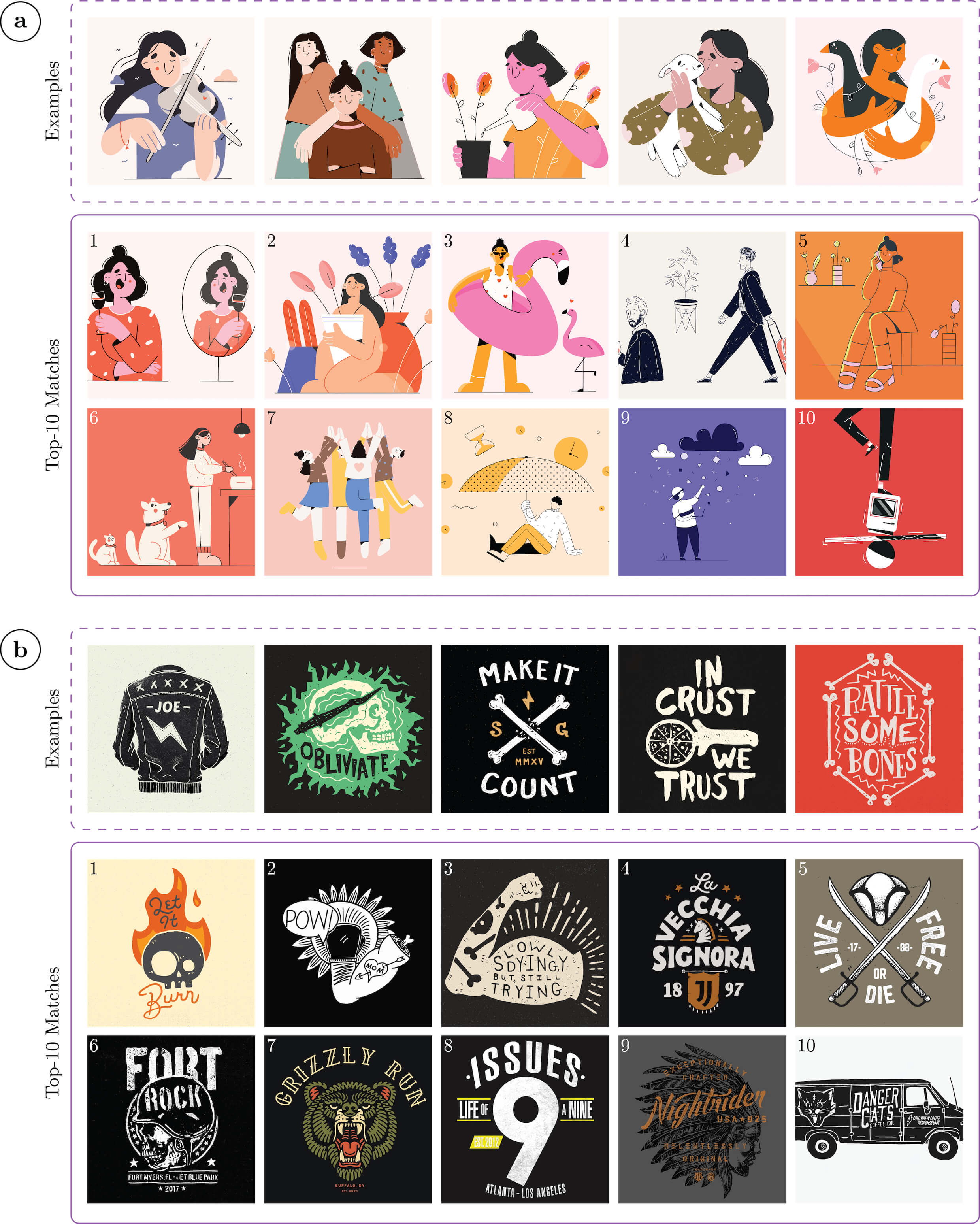
(a) and (b) show two example query results. The dashed lines contain the positive examples used for training. The solid lines contain the queried samples with the highest match scores, ranked from 1 to 10.
III. Applications
To wrap up, we suggest potential applications of PseudoClient for augmenting designers.
- Search. A natural application of PseudoClient is an example-based, style-based search engine. Unlike existing search tools built into many design sharing websites, a search engine built on top of PseudoClient does not require the designs to be manually tagged with keywords.
- Feedback. PseudoClient can also provide rapid, automatic design feedback to the designer for evaluating how well the designer’s design draft aligns with the client’s personal style.
- Generation. Finally, PseudoClient can be used as key component in generative design methods where PseudoClient can guide the rapid exploration of multiple design alternatives.
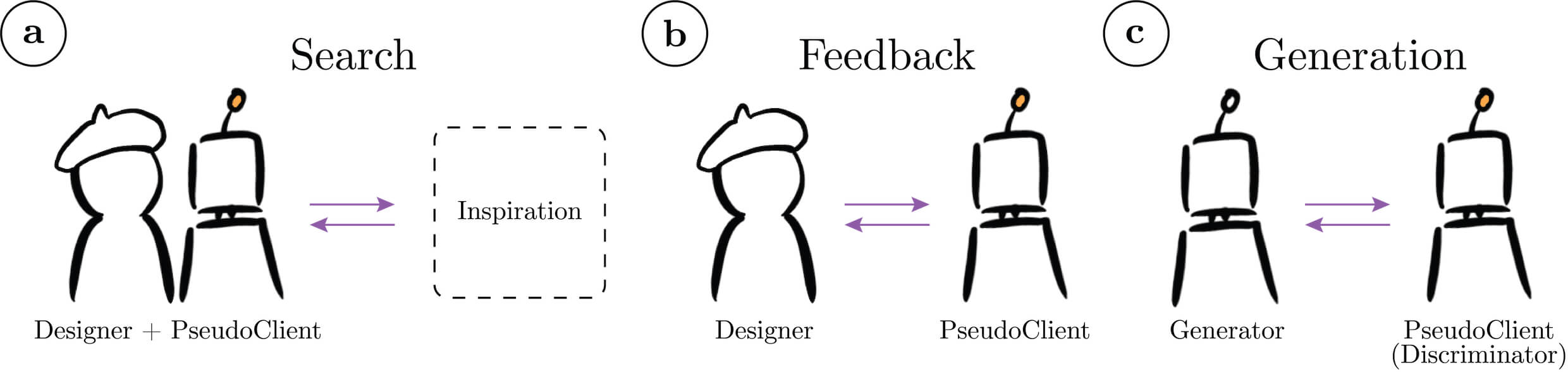
PseudoClient can be used as a building block for multiple practical design applications. We explore applications from three directions: (a) search, (b) feedback, and (c) generation.
Acknowledgments
This work is supported by a gift from Accenture Technology Labs. The beautiful illustrations are by Zach Rupert, Tatooine Girl, Ivan Dubovik, Justin Bryant, Aleksandr Reva, Maycon Prasniewski, Hanna Ak, Tyler Thorny, Tatak Waskitho, Kane Young, Rick Barker, Paulius Kolodzeiskis, Anna Shulha, Vee Are, Evan Brown, and Jeff Trish.